Spark(Google Dataproc)から、AWS S3にアクセスする方法です。
手順
Spark設定
下記のSpark・Haddopの設定をすると、SparkからAWS S3ファイルの読み書きができるようになります。
- Sparkに下記AWS関連のjarファイルを読み込みます
- aws-java-sdk-bundle-xxxx.jar
- hadoop-aws-xxxx.jar
- Hadoopの設定ファイル「core-site.xml」に下記パラメータを設定します
- fs.s3a.access.key:AWS S3のアクセスキー
- fs.s3a.secret.key:AWS S3のシークレット
Dataproc設定
Dataproceはマネージドサービスのため、Sparkを直接いじることができません。
代わりに、Dataproceの「クラスタープロパティ」と「初期化アクション」を使って、 クラスター作成時にSpark・Hadoopの設定します。
下記の初期化アクションを作って、Google Cloud Storageにアップします。
init_action.sh
#!/bin/bash JAR_PATH=/usr/local/lib/jars mkdir $JAR_PATH # AWS S3 HADOOP_PATH=/usr/lib/hadoop-mapreduce HADOOP_AWS=hadoop-aws-2.9.2.jar AWS_JAVA_SDK_BUNDLE=aws-java-sdk-bundle-1.11.199.jar ln -s $HADOOP_PATH/$HADOOP_AWS $JAR_PATH/hadoop-aws.jar ln -s $HADOOP_PATH/$AWS_JAVA_SDK_BUNDLE $JAR_PAth/aws-java-sdk-bundle.jar
初期化アクションでは、Sparkに追加するjarファイルの置き場所を作って、 そこに「aws-java-sdk-bundle-xxxx.jar」と「hadoop-aws-xxxx.jar」へのシンボリックリンクを設定しています。
クラスター作成
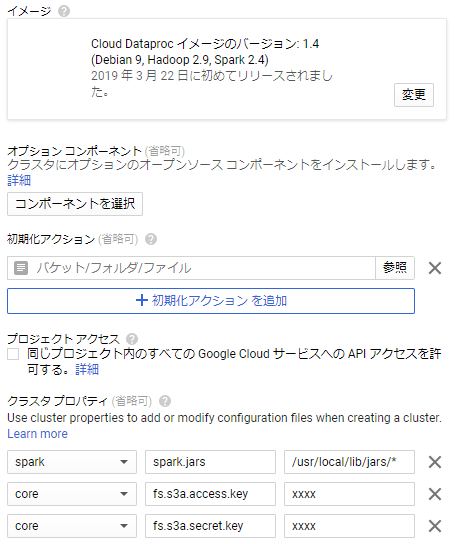
- イメージ
- AWS関連のjarファイルは、イメージのバージョン1.4以降から同封されるので、クラスターイメージをバージョン1.4以降にします。
- 初期化アクション
- 先程Google Cloud Storageにアップした初期化アクションファイルを指定します
- クラスター作成時に、このアクションが実行されます
- クラスタプロパティ
- [spark]:[spark.jars]:[/usr/local/lib/jars/*]
- 「spark」でSparkの設定「spark-defaults.conf」を設定します
- 「spark.jars」「/usr/local/lib/jars/*」で、SparkにJDBCのjarファイルを読み込ませます
- [core]:[fs.s3a.access.key]:[xxxx]、[core]:[fs.s3a.secret.key]:[xxxx]
- 「core」でHadoopの設定ファイル「core-site.xml」を設定します
- 「fs.s3a.access.key・secret.key」でAWS S3のアクセスキーとシークレットを設定します
- [spark]:[spark.jars]:[/usr/local/lib/jars/*]
AWSのjarファイルの名前は変わる可能性があるので、ファイルが見つからない場合は、クラスターのマスターノードにSSHログインしてファイル名を確認します。
利用例
df = spark.read.format("json").load("s3a://xxxx/xxxx/test.json") df.show()
その他感想等
読み書き両方が可能です。
S3のパスは、「s3」ではなく「s3a」なので注意が必要です。