GCPのKubernetes(GKE)で、プログラムでエラーが発生したら、Slackやメールなどの外部に通知する方法です。
自分でエラー検知の仕組みを実装しなくても、GCPの設定のみで可能です。
大まかな仕組み
プログラムでエラーが発生した時に、プログラムから標準エラーにメッセージを出力するようにします。
GKEでは標準で、コンテナの標準出力および標準エラーをCloud Loggingにログとして出力してくれます。
Cloud MonitoringでCloud Loggingのログを監視して、出力があった時に外部通知するようにします。
GCPの仕組み
GKEとCloud Logging
GKEでクラスターを作成すると、デフォルトで各種ログがCloud Loggingに出力されるようになります。
ログにはコンテナからの標準出力・標準エラーも含まれていて、プログラムからは意識することなしに、標準出力・標準エラーに対して出力さえしておけば、同じものがCloud Loggingにも出力されてログとして残ります。
Cloud Monitoring
Cloud Monitoringとは、様々な指標データを蓄積して、そのデータからグラフを作成するツールです。
例えば、インスタンスのメモリ使用量データをCloud Monitoringに定期的に送るようにして、グラフにして監視するといったことができます。
Cloud Monitoringの機能の一つに、指標に条件を設定して、条件に一致した時に外部に通知を送ることができます。
今回はその機能を使って、コンテナから標準エラーに出力があった時に外部通知を送るようにします。
Cloud Monitoringはログ監視に近い印象ですが、指標はログというより、時系列に登録されていくデータベースのレコードのようなもので、Cloud Monitoringは、指標データベースと、そのデータベースの可視化・監視ツールがセットになったようなサービスです。
Cloud MonitoringとCloud Loggingの組み合わせ
Cloud Loggingは単なるログなので、ログをCloud Monitoringで監視するには、ログからCloud Monitoringに指標としてデータを送るようにします。
具体的には、Cloud Loggingで監視したいログを表示するクエリを書き、そのクエリをCloud Monitoringの指標として登録します。
すると、Cloud Loggingが定期的にそのクエリを実行し、実行結果のログ件数を、Cloud Monitoringへ指標として送るようになります。
後はCloud Monitoringで、その指標に値が入った時に、外部に通知を送るように設定すると、ログに出力があると外部に通知が送られるようになります。
手順
コンテナ
コンテナからは標準エラーに出力するだけです。
例)標準エラー出力アプリ
package main import ( "fmt" "os" "time" ) func main() { for { m := time.Now().Minute() for i := 0; i <= m; i++ { fmt.Fprintf(os.Stderr, "stderr message : %+v/%+v\n", i, m) } fmt.Println("stdout message") time.Sleep(2 * time.Minute) } }
Cloud Logging
指標を作る
Kubernetesからは、Cloud Loggingに様々なログが出力されているのですが、Cloud Loggingの「ログビューア」では、「ログ フィールド エクスプローラ」でマウスでポチポチやるだけで、多数のログの中から、指定のログに絞り込んで表示することができます。
例えば、前述のコンテナのエラーログを表示します。
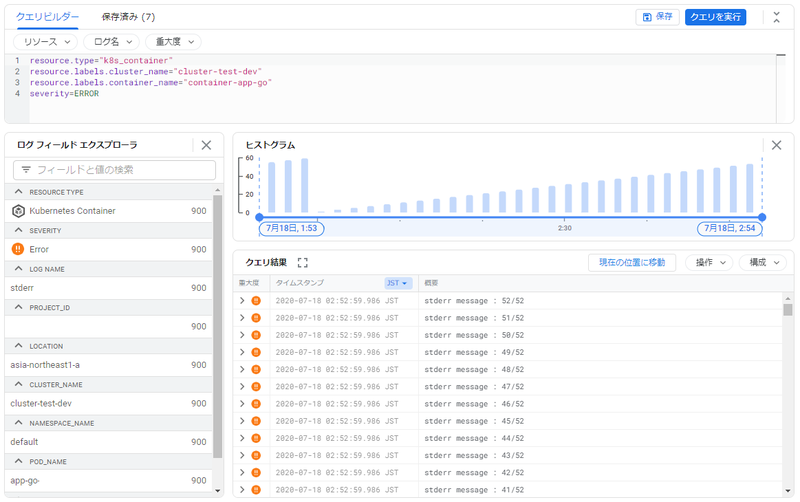
絞り込み方法はクエリとして作成されます。
resource.type="k8s_container" resource.labels.cluster_name="cluster-test-dev" resource.labels.container_name="container-app-go" severity=ERROR
このクエリのログ件数を指標として登録します。
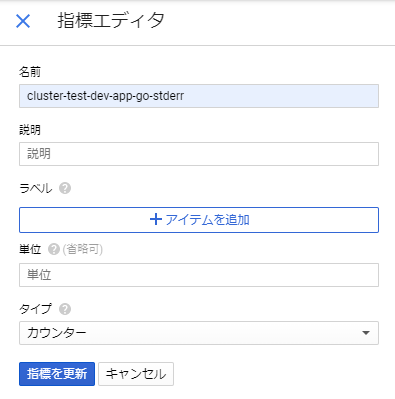
- 「指標を作成」をクリックします
すると「指標エディタ」が開くので、「名前」および、タイプを「カウンター」にセットして、「指標を作成」をクリックすると、このクエリを満たすログの件数を出す、オリジナルの指標が作成されます。
クエリは正規表現なども使えるので、pod単位でエラーログを絞り込むなど、柔軟な指定が可能です。
アラートを作る
後は、Cloud Monitoringで、先程作成した、コンテナのエラーログ件数指標でアラートを作成します。
流れ
ちょっとややこしいので、ログからアラート検知および、アラート終了までのデータの流れを先に記載します。
- ログベースの指標は、1分毎にクエリを実行して、実行結果の件数をCloud Monitoringに送ります。クエリ結果が0件でも値0の指標として登録されます
- 記録されたログ件数を、任意の方法で集計(計算)します。
- 例えば、「5分毎に件数の合計を求める」など
- 集計結果をチェックして、指定期間中条件を満たすとアラートを発生させます。
- 例えば、「1時間の間、集計結果が常に0以上の場合にアラート発生」など
- アラートが発生してから、条件を満たさなくなると、アラートは終了します。
- アラートが条件を満たす限り、新しい通知は送られません。
作成
指標から集計を行います。
[Cloud Logging]-[ログベースの指標]-[ユーザー定義の指標]
で作成したログベースの指標の右の「...」で「指標に基づいて通知を作成する」にします。
すると、Cloud Monitoringの通知ポリシー作成に遷移します。
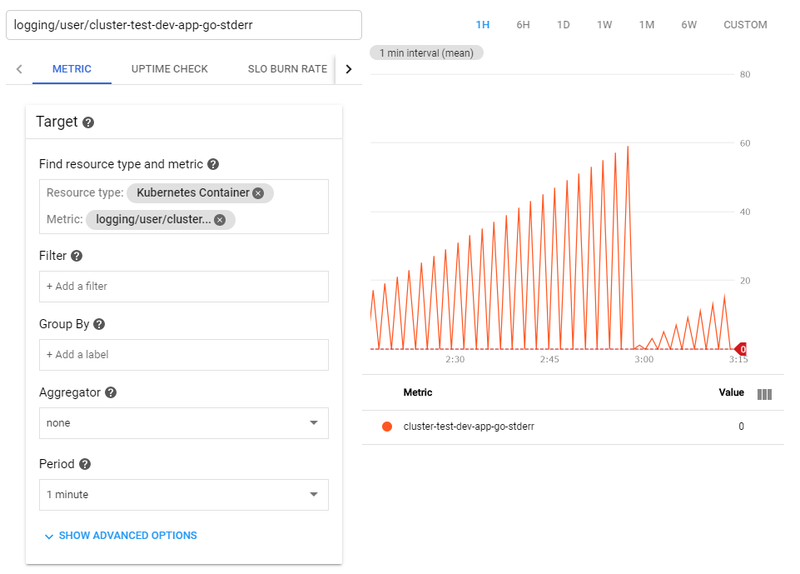
ログベースの指標は「logging/user/~」という名前で指標として登録されているので、通知ポリシーの「Metric」にその名前が設定されています。
集計指定
Cloud Monitoringには、ログベースの指標が記録されていきます。そのままだと単なるログ件数データなので、それを使って、何を集計(計算)するかを決めます。
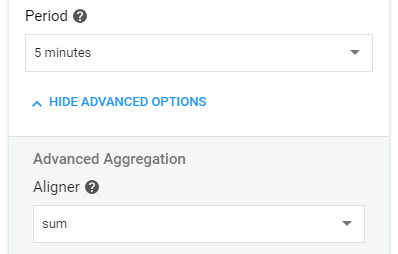
例えば、5分毎に件数を集計します。
AggregatorをnonePeriodを5 minute[Advnced Aggregation]-[Aligner]をsum
にします。
条件指定
「Configuration」で、上で集計した値がどうなったらアラートになるかを設定します。
例えば、1分間の間、常に1件以上エラーがあったら通知にします。
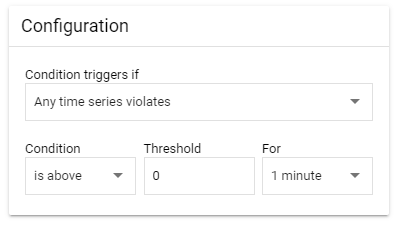
[Configuration]-[Threshold]を0
これで、1分間の間、常に1件以上エラーがあったら通知が送信されます。
条件を満たしている間はアラートが続いていると判定されて、新たな通知は行われません。
条件を満たさなくなると、そのアラートは終了となり、次に条件を満たすと新しくアラートが発生して通知が行われます。
通知先指定
後は通知先を指定すると、アラートが発生すると、通知先に通知が行きます。
例)メール通知
Cloud Monitoring 補足説明
Cloud Monitoringでいくつかハマったので、使い方を簡単にまとめておきます。
Aggregatorについて
指標からグラフを作成する際、ログベースの指標は1つしかないのでグラフは1本ですが、インスタンスのメモリ使用量指標などだと、インスタンスの数だけグラフが表示されます。そして複数のグラフを1つにまとめる方法をAggregatorで指定します。今回のように、グラフ(指標)が1つしかない場合は、Aggregatorをnoneにします。
Alignerについて
Cloud Monitoringは柔軟に作られていて、受け取った指標の値をそのまま表示するのではなく、任意の集計をして表示します。そして、その集計方法を[Advnced Aggregation]-[Aligner]で指定します。
今回のように、ログ件数(指標)を求めるにはsumにしますし、期間中の最大値を取りたい場合はmaxにします。
countがあるのですが、これはログ件数のことではなく、ログベースの指標が送られた回数のことです。ですので、ログ件数が0でも、指標が登録された回数がカウントされます。
そして、ログベースの指標は1分毎に送られるので、例えばPeriodを10 minuteにすると、countは10になります。
Configuration について
上記で指定した、指標の集計結果が、どれだけの期間条件が続けば、異常状態とするかを指定します。
例えば、エラーログを検知したらアラートとする場合は、1分間の間に1件以上あればアラートとします。
ここで指定する期間は、チェック頻度の期間ではなく、条件を満たし続ける期間です。
例えばチェック頻度を1時間毎にする場合は、ここでの頻度を1時間にするのではなく、集計頻度を1時間にします。
集計頻度を1分にして、ここでの期間を1時間にすると、60分間エラーが出続けた場合にエラーという条件になります。その場合、60分の間に1度でもエラーが無い時があると、条件は成立しません。
ログベースの指標は1分毎にデータが送られてきますが、指標によっては、不定期にデータが送られてくるものもあります。そういった場合、条件成立に使われる値はどうなるかというと、一番最後に取得した指標がそのまま続いているとして扱われます。
例えば、集計頻度を1時間にして、ここでの頻度を10分にすると、エラーが発生して集計でエラー件数が0以上になった後、その状態が1時間続くことになります。そして、それはエラーが集計されてから10分間その状態が続いていることになるので、結果として10分後にアラートが成立します。そして、そのまま50分間エラー状態が続き、その間アラートは解除されません。そして次の集計でエラーが0件になると、アラート状態が解除されます。
感想など
Cloud LoggingとCloud Monitoringを組み合わせて使うので、ドキュメントやUIが分散していてちょっととっつきにくいですね。
ハマりポイントとしては
- Cloud Loggingそのものは単なるログで、アラート機能はなく、ログから指標を作成して、その指標を介してCloud Monitoringからアラートを生成する
- ログベースの指標は、ログが記録されると登録されるのではなく、常に一定間隔でクエリを実行し、その実行結果を登録している
- クエリの実行結果が0件でも指標として登録される
- Cloud Monitoringは指標をそのまま使うのではなく、一定間隔の集計結果を使う
- アラートは、指定期間中その状態を満たし続けた場合に発生する
- アラートの指定指定期間中に新しい指標が登録されなかった場合は、最後の指標が継続して用いられる
といったところでしょうか。Cloud Monitoringの設定がちょっとややこしいですね。
ベンダー依存のテクニックなので、ちょっと調べて理解できる範囲に使用は留めておいて、あまり深追いはしないでおこうと思います。