GCP関連でプログラムを作っていて、ちょっとしたデータを保存したいことがありました。
データベースを立てるほど大げさなデータでもないし、データ間で結合クエリを書くこともなさそうな単発のデータでした。
そもそも、データベースを立てると、使っていない時もインスタンスの料金が発生するので、データベースを立てるのは選択肢から外しました。
Google Cloud Storageに保存するのが良さそうだったのですが、Firestoreも同様の用途に使えそうだったので、今回Firestoreを使ってみました。
これからも手軽にFirestoreを使っていきたいのですが、FirestoreはCloud Storegeほど直感的ではなく、使うにはある程度のFirestoreの知識が必要なので、ここに使い方をメモしておこうと思います。
Firestoreとは?
Firestoreは,元々はFirebaseのデータベースで、GoogleがFirebaseを買収したに伴い、GCPのデータベースの1つとして提供されるようになりました。
本来Firebaseでの利用が主目的だったとあって、ウェブサービスのデータのように、大量かつ頻繁に読み書きされるデータを保存するのに向いています。
また、Firebaseの売りでもあるのですが、ブラウザのJavaScriptライブラリが充実していて、Firestoreを扱うバックエンドを用意しなくてもブラウザから直接Firestoreを扱えるので、ウェブアプリだけでウェブサービスを構築することができます。
そういったウェブサービス向けデータベースの印象が強いFirestoreですが、今回のように、ちょっとしたデータの読み書きに使っても問題ありません。
ここでは、そういったちょっとしたデータの読み書き向けの解説をしようと思います。
ざっくり説明
Firestoreは、いわゆるキーバリューストア、NoSQLと呼ばれるもので、データベースというより、階層に分けて分類できるメモ帳のようなものです。
メモ帳の中身は、ユーザーが好きなようにJSONでデータを保存できます。
Firestoreの中身はCloud Storageのように、キー(パス)と実態ファイルで構成されて、キーを後述するコレクションとドキュメントの階層で表現し、そのキーの場所にJSONデータを保存します。
はじめに
Firestoreを理解するには、Google Cloud StorageやAWS S3、Azure Blobなどの、ストレージをイメージしてもらうといいかと思います。
これらのストレージは、ファイルの場所を示すキーとデータで構成されます。
キーは一見ディレクトリ構造のよう見え、ファイルシステムのように、ディレクトリがあって入れ子になっているように見えます。
しかし、キーをディレクトリ構造のように見えるように書いているだけで、あくまでキーとデータは1対1対応で、ディレクトリというものは存在しません。
Firestoreも一見ディレクトリ構造のように見えますが、ストレージ同様、あくまでキーとデータは1対1対応で、入れ子構造ではありません。
この仕組みを意識しならが見ると、Firestoreの挙動が理解しやすくなります。
構成
ドキュメント- 最終的にデータが保存される、ファイルのようなものです。ファイル同様、名前が存在します。
コレクション- 複数の
ドキュメントを格納する、配列のようなものです。
- 複数の
参照ドキュメントやコレクションの位置を示す、ファイルで言うところのフルパスのようなものです。
例)ドキュメント作成
例えば、userのコレクションに、123のユーザーをドキュメントに登録する場合は下記のようになります。
const ref = db.collection('user').doc('123'); await ref.set({ user_id: 123, user_name: "ABC", user_mail: "abc@exampble.com" });
db.collection('user').doc('123')がドキュメントの位置を示す参照で、その参照の場所にset()でデータを書き込んでいます。
コレクションやドキュメントは予め作成しておく必要はありません。
例)ドキュメント取得
ドキュメントを取得するのは下記のようになります。
const ref = db.collection('user').doc('123'); const doc = await ref.get(); if( doc.exists ){ console.log(doc.data()); }
ドキュメントの位置を示す参照を作成し、その参照をget()します。
参照にドキュメントが存在するか.existでチェックし、存在するならdata()で保存されているデータを取り出します。
ドキュメント名の省略
一般的なデータベースの場合、userテーブルにユーザーデータを登録する場合、ただデータだけを登録していきます。
しかし、Firestoreの場合、userテーブルにあたるものを、userのコレクションだとすると、ユーザーデータは123のドキュメントとなり、ユーザーデータとは別に、123というドキュメント名を登録する必要があります。
Firestoreはキーバリューストアなので、ユーザーデータを指定する参照にドキュメント名を指定しないと、そのドキュメントがどこかを示せないので当然と言えば当然なのですが、Firestoreをデータベースのように扱いたい場合は、都度重複しないドキュメント名を生成して設定するのが面倒になることがあります。
そういった場合は、ドキュメント登録時にドキュメント名を省略すると、Firestoreが自動で重複しないドキュメント名を生成してくれます。
ドキュメント名の省略した場合は下記のようになります。
const ref = db.collection('user').doc(); // document name -> UOSnkhyz07BBwwcReeBL console.log(`document name -> ${ref.id}`); await ref.set({ user_id: 123, user_name: "ABC", user_mail: "abc@exampble.com" });
自動生成されたドキュメント名はref.idに格納され、その参照でset()したドキュメントの名前になります。
登録したドキュメントを取得するには、ドキュメント名は使わず、後述するクエリを使って、登録されたデータを検索して取得します。
const queryResult = db.collection('user').where('user_id', '==', 123).get(); if( !queryResult.empty ){ console.log(queryResult.docs[0].data()); }
階層
コレクションやドキュメントは階層にできます。
例えば、groupのコレクションに、各グーループを作成し、その中にそのグループのuserを登録するには下記のようになります。
const ref = db.collection('group').doc('groupA').collection('user').doc('123'); await ref.set({ user_id: 123 });
ここでも、コレクションやドキュメントは予め作成しておく必要がなく、途中に実在しないコレクションやドキュメントを参照に使うことができます。
参照のパス表記
こうやって見ると、参照はまさに参照で、ファイルにおけるフルパスのようなものであるのが分かりますね。
上記の例をファイルのパスのように見ると、ユーザーオブジェクトはgroup/groupA/user/123とも言えます。そして、実際にこの書き方で参照を指定することができます。
上記の例を参照のパス表記で書くと下記のようになります。
const ref = db.doc('group/groupA/user/123'); await ref.set({ user_id: 123 });
階層の注意 その1
Firestoreの階層で気をつけなければいけない点は、コレクションとドキュメントは階層にできますが、コレクションとドキュメントは交互に繋がないといけません。
コレクションの後にコレクションが続いたり、ドキュメントの後にドキュメントが続くような階層は作れません。
不便なのですが、Firestoreのルールなので従うしかありません。階層を使う際は、オブジェクトが丁度コレクションの後になるように階層を作る必要があります。
階層の注意 その2
もう1つFirestoreの階層で気をつけなければいけない点は、上位階層のドキュメントを削除しても、その下の階層のドキュメントは削除されず残り続けることです。
Firestoreはキーバリューストアなので、下層のドキュメントを指す参照は、あくまでそのドキュメントのキーであって、そのキーに書かれている上層のドキュメントが実在するか否かはキーとは無関係なのです。
例えば上記例のgroupAドキュメントは、別途set()で明示的に作成されていない場合は、実在しません。
ただ、ドキュメントが残り続けるのは、プログラムから削除した場合で、GCPのコンソールから削除すると、GCPが裏で下層の全てのオブジェクトを削除してくれます。コレクション・オブジェクトを上層からごっそり削除したい時は、GCPのコンソールで削除するのが楽でおすすめです。
階層の注意 その3
最初に記載したとおり、Google Cloud Storegeのようなストレージは、ディレクトリがあって入れ子構造になっているように見えますが、実際にはディレクトリは存在せず入れ子構造にはなっていません。
Firestoreも同様で、コレクションがあって入れ子構造になっているように見えますが、実際にはコレクションは存在せず入れ子構造になっていません。
あくまで、ドキュメントを生成する時の参照にコレクションを記述して、コレクションにオブジェクトが属しているように見せているだけです。
ですので、コレクションだけを作成することはできず、オブジェクトの生成の過程で生まれます。
同様に、コレクションを削除することはできず、参照にそのコレクションを含む全てのドキュメントを削除することにより、そのコレクションが削除されます。
データ更新
データの更新は、更新する項目だけをセットしたデータを登録することにより行います。
const ref = db.collection('user').doc('123'); await ref.update({ user_name: "XYZ", user_mail: "xyz@example.com" });
注意点
Firestoreは、入力したデータの項目を上書きすることにより更新します。
ですので、項目が配列やオブジェクトだった場合、入力したデータの配列やオブジェクトに置き換わります。つまり、そのままでは、配列の要素を追加したり、オブジェクトの設定した項目だけを更新することはできません。
それをやるには、特殊な関数を使ったり、特殊な記述方法を使う必要があるのですが、ここでの説明は省略します。
個人的には、軽量データベース代わり程度の利用であれば、配列やオブジェクトを更新する場合、一旦データを取得して、そのデータを更新して、ドキュメントの全データをまるっと上書きする方法でいいんじゃないかと思っています。
クエリ
コレクションの中からドキュメントを取り出すにはクエリを使います。
クエリの使い方は簡単で、コレクションの参照のget()メソッドを呼び出すだけです。
where()やorderBy()を間に挟むことにより、条件による絞り込みや並びの設定が行なえます。
クエリ実行の結果、取得したドキュメントはdocs配列に格納されます。
let queryResult = await db.collection('user').get(); if( !queryResult.empty ){ queryResult.docs.forEach(doc=>consoel.log(doc.data())); } queryResult = await db.collection('user').where('user_name', '==', 'ABC').get(); if( !queryResult.empty ){ queryResult.docs.forEach(doc=>consoel.log(doc.data())); }
ページング
クエリ結果が大量にある場合などは、ページングを行います。
ページングはstartAfter()とlimit()とorderBy()を使ってユーザーが実装します。
let queryResult = await firestore.collection('user') .orderBy('user_id') .limit(2) .get(); while (!queryResult.empty) { const docs = queryResult.docs; docs.forEach((doc: any) => console.log(doc.data())); queryResult = await firestore.collection('user') .orderBy('user_id') .startAfter(docs[docs.length - 1]) .limit(2) .get(); }
startAfter()は指定したドキュメント以降のドキュメントを取得します。
ですので、orderBy()で並びを明確にした上で、limit()でページの取得件数を指定し、2ページ目以降は前回取得した最後のドキュメントをstartAfter()に指定し、それに続くドキュメントを取得するようにします。
存在しないドキュメント
これまで何度か述べてきたとおり、ドキュメントの参照で、上層のドキュメントが存在しないパスを指定することができます。
例えば下記の場合、groupAのドキュメントを作成していなくても、123のドキュメントを作成することができます。
const ref = db.collection('group').doc('groupA').collection('user').doc('123'); await ref.set({ user_id: 123 });
この結果をGCPのFirestoreのコンソールで見ると、groupAは表示されているのですが、斜体になっていて、そのドキュメントは存在しないことが分かります。
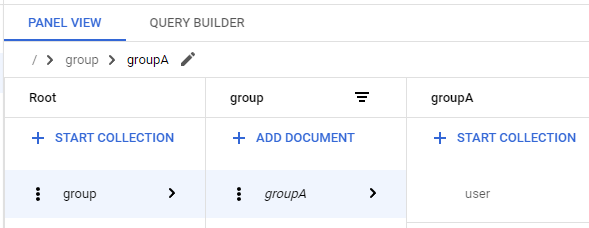
これにgroupAを追加してみます。
const ref = db.collection('group').doc('groupA'); await ref.set({});
すると、groupAが通常体になり、groupAが存在しているのが分かります。
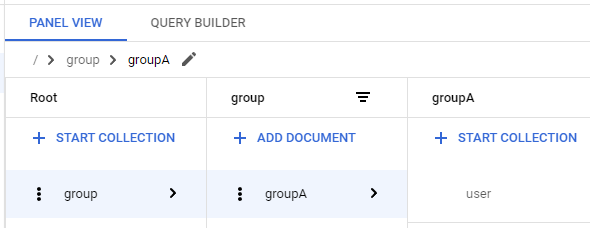
ここでgroupAを削除してみます。
const ref = db.collection('group').doc('groupA'); await ref.delete()
すると、再度groupAが斜体になり、groupAが削除されたのが分かります。
しかし、groupAの下にあったuserのコレクションと、図には表示されていませんが、その下の123のドキュメントは削除されずに残っています。
存在しないドキュメントを取得する
通常のクエリでは、存在しないドキュメントは取得できません。
存在しないドキュメントを含む、コレクション直下のドキュメント一覧を取得するには、コレクションの参照のlistDocuments()を使います。
const ref = db.collection('group'); const docs = await ref.listDocuments(); docs.forEach(doc => console.log(doc.id)); // groupA
まとめ
最後に、スニペット的にまとめを書いておこうと思います。
流れ
下記のドキュメントの参照からドキュメント取得までの流れ、および、コレクションの参照からドキュメントの配列取得までの流れを、意識するといいかと思います。

要素・関数
各クラスでよく使う要素・関数です。
| クラス | 要素・関数 | 概要 |
|---|---|---|
| ドキュメントの参照 | ||
| id | ドキュメント名 | |
| path | パス | |
| get() | ドキュメント取得 | |
| set() | データ追加・上書き | |
| update() | データ更新 | |
| delete() | 削除 | |
| listCollections() | 所有コレクション一覧 | |
| ドキュメント | ||
| exists | 存在チェック | |
| id | ドキュメント名 | |
| ref | ドキュメントの参照 | |
| createTime | 作成日時 | |
| updateTime | 更新日時 | |
| data() | データ取得 | |
| コレクションの参照 | ||
| id | コレクション名 | |
| path | パス | |
| get() | クエリ実行 | |
| limit() | 件数指定 | |
| startAfter() | 指定ドキュメント以降を取得 | |
| where() | 絞り込み | |
| orderBy() | 並び替え | |
| listDocuments() | 所有ドキュメント一覧 (存在しないドキュメントを含む) |
サンプルコード
ドキュメント作成
const ref = db.collection('user').doc('123'); await ref.set({ user_id: 123 });
const ref = db.collection('user').doc(); await ref.set({ user_id: 123 });
const ref = db.doc('user/123'); await ref.set({ user_id: 123 });
ドキュメント取得
const ref = db.collection('user').doc('123'); const doc = await ref.get(); if( doc.exists ){ console.log(doc.data()); }
ドキュメント更新
const ref = db.collection('user').doc('123'); await ref.update({ user_data: 456 });
ドキュメント削除
const ref = db.collection('user').doc('123'); await ref.delete();
クエリ
const queryResult = await firestore.collection('user').get(); if( !queryResult.empty ){ for(const doc of queryResult.docs){ console.log(doc.data()); } }
ページング
let queryResult = await firestore.collection('user') .orderBy('user_id') .limit(2) .get(); while (!queryResult.empty) { const docs = queryResult.docs; docs.forEach((doc: any) => console.log(doc.data())); queryResult = await firestore.collection('user') .orderBy('user_id') .startAfter(docs[docs.length - 1]) .limit(2) .get(); }
感想など
昔、GCPの初期のDatastoreを使ったことがあるのですが、それと比べるとFirestoreはとっつきやすいですね。
最初、ディレクトリ構造をイメージして混乱しました。Firestoreをディレクトリ構造と捉えると、変に感じる挙動があるのですが、キーバリューストアと捉えると納得がいきました。
Firestoreは前準備の必要なく、いきなりパスを書いて、そこにデータを保存できて便利です。
まずはメモ帳のように、単発データ保存の場所として使っていこうと思います。