Markdownを読み込んで、色々好きなように編集して、再度Markdownに出力したいことがありました。
その際、remarkというJavaScriptのMarkdownパーサーを使いました。
ただ、使い方が分かりにくく、次にプログラムの修正が必要になった時には確実に使い方を忘れていそうなので、ここに今回の使い方を備忘録として残しておこうと思います。
構成
とにかく関連ライブラリが色々登場してくるので全体像がつかみ辛く混乱しました。どこから説明していいのか迷うのですが、とりあえず端から説明していこうと思います。
何をするのか?
「テキスト(マークアップ言語)からAST木(構造木)を作成し、そのAST木を解析・変換して、再度テキスト(マークアップ言語)に出力する」ためのフレームワークを作ろうというプロジェクトがあります。
そのプロジェクトがunifiedです。
unifiedはあくまでフレームワークで、どのマークアップ言語を読み込んで、どのマークアップ言語で出力するかは、プラグインとして外部で定義するようになっています。
そして、今回はテキストとしてMarkdownを使用しましたが、その「Mardownを読み込んでAST木を作る」「AST木からMarkdowを出力する」ためのプラグインがremarkです。
プラグインがあるマークアップ言語はMarkdowのみでなく、HTMLやXMLもあります。また、MarkdownのAST木をHTMLのAST木に変換したり、その逆の変換をするプラグインもあります。
それらにより、unifiedと各種プラグインを使って、下記のような処理が行なえます。
- MarkdownテキストからプラグインでMarkdown AST木を作成
- Markdown AST木をプラグインでHTML AST木に変換
- HTML AST木からプラグインでHTMLテキストに出力
この一連処理で、MarkdownをHTMLに変換、といったことができるようになります。
注意
調べた範囲では、AST木の別のマークアップ言語のAST木への変換プラグインは「MarkdownからHTML」と「HTMLからMarkdown」だけしかないようでした。
AST 木
ベースとなるAST木がunistになります。
そして、unistを拡張してMarkdownを扱えるようにしたAST木がmdastになります。
また、unistを拡張してHTMLを扱えるようにしたAST木がhastになります。
AST木ユーティリティ
今回がそうだったのですが、AST木を自分で編集したいことがあります。
そんな時、よくやる操作や便利な機能が、unist-util-...という名前でいくつか用意されています。
unifiedの使い方
一連の処理をするものをprocesserと呼び、processerの実行関数を呼び出すことにより、processerに処理をさせます。
processerがどういった処理をするかは、processerにプラグインを追加していくことにより構築していきます。そして、プラグインの追加は.use(<plugin_name>)で行います。
processerは下記の3つのパートに分かれています。
- テキストからAST木を構築する
Parser - AST木を変形する
Transformers - AST木をテキスト出力する
Compiler(stringify)
それぞれのパートの実行は、processerの下記関数により行います。
processer.parse()はParserを実行processer.run()はTransformersを実行processer.stringify()はCompilerを実行processer.process()は全てを実行
例
MarkdownをHTMLに変換は、下記の流れ・使用プラグイン・コードになります。
- テキストからMarkdownのAST木を作成(
remark-parse) - MarkdownのAST木をHTMLのAST木に変換(
remark-rehype) - HTMLのAST木をテキストに出力(
remark-stringify)
import { unified } from 'unified'; import remarkParse from 'remark-parse'; import remarkRehype from 'remark-rehype'; import remarkStringify from 'remark-stringify'; const processer = unified() .use(remarkParse) .use(remarkRehype) .use(rehypeStringify); const markdownText = fs.readFileSync('./data/in/sample.md'); const markdownTree = processer .parse(markdownText); const htmlTree = await processer .run(markdownTree); const htmlText = processer .stringify((htmlTree as any)); console.log(htmlText);
processer.process()を使って1つにまとめることもできます。
const markdownText = fs.readFileSync('./data/in/sample.md'); const htmlText = await unified() .use(remarkParse) .use(remarkRehype) .use(rehypeStringify) .process(markdownText); console.log(htmlText);
プラグインオプションのドキュメントおよびunifiedを使わない方法
プラグインの挙動をカスタマイズしたい時は、プラグインのオプションを設定するのですが、プラグインはガワだけで、実装は別のライブラリがやっています。
例えばremark-parseプラグインの実装は、mdast-util-from-markdownライブラリが行っています。
使っているライブラリさえ分かれば、unifiedとプラグインを使わなくても同じことができます。
import { fromMarkdown } from 'mdast-util-from-markdown'; import { toHast } from 'mdast-util-to-hast'; import { toHtml } from 'hast-util-to-html' const markdownText = fs.readFileSync('./data/in/sample.md'); const markdownTree = fromMarkdown(markdownText); const htmlTree = toHast(markdownTree); const htmlText = toHtml(htmlTree); console.log(htmlText);
プラグインのオプションのドキュメント
オプションのドキュメントはプラグインのページにはなく、ライブラリのページにあります。
ですので、まずプラグインがどのライブラリを使っているかを知る必要があります。
プラグインがどのライブラリを使っているかは、ライブラリのドキュメントを注意深く読んでいると分かるのですが、それでも見つからない場合は、プラグインのソースのindex.js見て、インポートされているライブラリを調べます。
AST木の解析
生成されたAST木を解析・変換方法を説明します。
出力されるAST木は、JavaScriptのObjectです。
簡略化して説明すると、基本ノードはunistで定義されています。基本ノードは、種類を表すtypeと、子ノードを格納するchildren配列で構成されます。
interface Node { type: string; }; interface Parent extends Node { chilren: Node[] };
そして、各マークアップ言語のAST木は、この基本形を拡張して、各々独自の要素が付与されています。
JavaScriptのObjectなので、自前で好きなように解析・変形させて構わないのですが、作業が楽になるよう、トラバースするユーティリティunist-util-visitが用意されています。
トラバース
unist-util-visitにAST木を渡すと、全てのノードで指定した関数を呼び出してくれます。
node現ノードparent親ノードindex現ノードを親ノードから見た子供の位置
import { visit } from 'unist-util-visit' visit(tree, (node, index, parent) => { console.log(node); });
修正
トラバース時にノードのデータを修正することができます。
ただし、unist-util-visitはImmutableではなく、入力AST木を修正するので注意が必要です。
visit(tree, (node, index, parent) => { if (node.type === 'text') { if (node.value) { node.value = 'TEST'; } } });
変形
ノードをトラバースして、子を「削除」「追加」「統合」することもできます。その際、先程同様、unist-util-visitはImmutableではなく、入力AST木を修正するので注意が必要です。
トラバースの順序は下記の順で行われます。
- 自分
- 子供
- 次の兄弟
例えば下記図の場合A - B - D - F - G - E - Cの順でノードが呼び出されます。
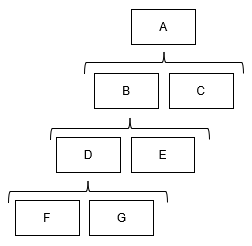
注意点
親がchildren配列を操作するのではなく、子が親のchildren配列を操作し、children配列の操作にはArray.slice()を使います。
例
typeがtextのノード削除するには、下記のようになります。
import { visit, SKIP, CONTINUE } from 'unist-util-visit'; visit(tree, (node, index, parent) => { if (node.type === 'text') { parent.children.slice(index, 1); return [SKIP, index]; } });
returnの意味は次に説明します。
次のトラバース対象ノード
returnでその後のトラバースの順序を変えることができます。returnをしないと、通常の規則に則ってトラバースが行われます。
子指定
通常、次にトラバースされるのは子ノードになりますが、returnの配列の1つ目にSKIPを設定すると、子ノードのトラバースはされません。
前述の例では、自分ノードを削除しているので、自分の子ノードがトラバースされないよう、SKIPを指定しています。
CONTINUEを指定すると、自分の子ノードがトラバースされます。
兄弟指定
自分の子ノードおよび、その子孫ノードのトラバースが終わった後、兄弟ノードのトラバースが行われるのですが、その兄弟の位置を、returnの配列の2つ目に指定します。
位置は親におけるchildren配列のインデックスになります。
自分ノードを削除したり、兄弟ノードと統廃合した場合、自分の次の兄弟の位置が変わってしまうので、次にトラバースするはずの兄弟がスキップされないよう、ここで指定します。
前述の例では、自分ノードを削除しているので、次の兄弟はかつて自分がいたindexになるので、その値を返しています。
実際の子供の数よりインデックス値が超えていてもエラーにはならないので、値チェックの必要はありません。
自作プラグイン
コーディングで独自の実装をする部分は、AST木の解析・変形部分になるかと思います。
その部分を、第1引数にtree、第2引数にfileを取る関数にまとめると、実装をプラグイン化できます。
function myPlugin(): any { return (tree: any, file: any) => { visit(tree, (node, index, parent) => { if (node.type === 'text') { node.value = 'TEST'; } }); }; } const outText = await unified() .use(remarkParse) .use(myPlugin) .use(remarkStringify) .process(inText);
感想など
remarkの使い方と言いながら、unifiedとunistの話になってしまいました。
実際、remarkを使うにあたってネックになるのは「unifiedの全体像把握」「AST木操作」「プラグイン内部で使用しているライブラリとそのオプションの調査方法」なので、そこを中心にまとめました。
プラグインをカスタマイズするにはオプションを設定するのですが、そのドキュメントに辿り着くまでが結構手間です。
また、プラグインを見ただけでは、そのプラグインが何をしているのか判断できません。
例えば、GitHub Flavored Markdown(GFM)のパースと出力にはremark-gfmプラグインを使います。
そして、テキストのGFMからGFMのAST木を作成し、再度テキストのGFMを出力するコードをunifiedを使って書くと下記のようになります。
import { unified } from 'unified'; import remarkParse from 'remark-parse'; import remarkStringify from 'remark-stringify'; import remarkGfm from 'remark-gfm'; const outGfmText = await unified() .use(remarkParse) .use(remarkGfm) .use(remarkStringify) .process(inGfmText);
これは内部では下記のような処理を行っています。
import { fromMarkdown } from 'mdast-util-from-markdown'; import { gfm } from 'micromark-extension-gfm' import { gfmFromMarkdown, gfmToMarkdown } from 'mdast-util-gfm' import { toMarkdown } from 'mdast-util-to-markdown'; const gfmTree = fromMarkdown(inGfmText, { extensions: [gfm()], mdastExtensions: [gfmFromMarkdown()], }); const outGfmText = toMarkdown(gfmTree, { extensions: [gfmToMarkdown()], });
remarkGfmプラグインは、parseとstrigifyに対し、GFM関連のエクステンションの追加を行っています。そして、remarkGfmプラグインのオプションは、そのGFM関連のエクステンションのオプションに引き渡されるので、remarkGfmプラグインのオプションの意味を知るには、GFM関連のエクステンションのオプションのドキュメントを参照する必要があります。
ですので、プラグインを使おうとすると、実際にソースを見て何をしているのか理解し、その中で使われているライブラリを見つけ出し、そのライブラリページに行ってドキュメントを見る必要があります。
この作業が超絶面倒くさいです!
最初、unifiedのお作法に則ってプログラムを書いていたのですが、オプションの挙動を確かめるため、ライブラリだけで書いてテストしているうちにプラグインに戻るのが面倒になり、結局unifiedは使わずライブラリだけ使うようになってしまいました。
最後に、参考までに各種変換とプラグインおよび、使われているライブラリの関連をまとめておきます。
| from | to | plugin | library |
|---|---|---|---|
| Text | Markdown AST | remark-parse | mdast-util-from-markdown |
| Markdown AST | Text | remark-stringify | mdast-util-to-markdown |
| Text | GFM Markdown AST | remark-gfm | mdast-util-gfm micromark-extension-gfm |
| GFM Markdown AST | Text | remark-gfm | mdast-util-gfm |
| Text | Html AST | rehype-parse | hast-util-from-parse5 |
| Html AST | Text | rehype-stringify | hast-util-to-html |
| Markdown AST | Html AST | remark-rehype | mdast-util-to-hast |
| Html AST | Markdown AST | rehype-remark | hast-util-to-mdast |