クローラーとしてPuppeteerを使っています。
クロールしていて、サイトのTableタグで作られた表のデータを取得したい時があります。
Pythonなら、htmlからTableタグ以下のみを抽出し、それからPandasを使ってDataFrameを生成することにより、エレガントにできちゃいます。
JavaScriptにも、TableタグのDOMから表データを作成し、それをCSV出力するライブラリはいくつかあります。
しかし、クロール先のサイトでライブラリを使うことはできないし、 クロール先のサイトページのDOMを、PuppeteerからNode.js側に直接持ってくることもできないので、 渋々自分でDOMをパースしていました。
でも、よくよく考えたら、Pythonのやり方同様、一旦サイトをhtmlで取得して、それを解析すればよかったんですね。
試しにやったらうまくいきました。
例
Wikipediaから、国別オリンピックメダル獲得数の表を、CSV出力してみます。
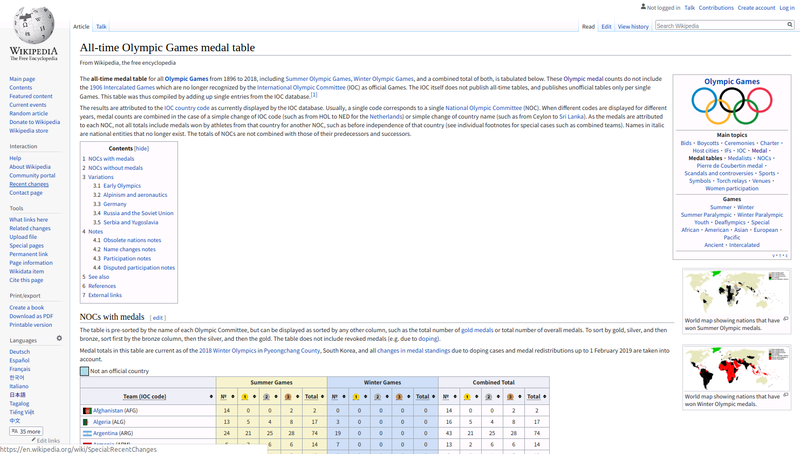
ページにある全てのTableタグをCSV出力するのは下記のようになります。
index.ts
import * as puppeteer from 'puppeteer'; import { JSDOM } from 'jsdom'; import * as XLSX from 'xlsx'; import * as fs from 'fs'; (async () => { const browser = await puppeteer.launch({ headless: false, slowMo: 250, }); const page = await browser.newPage(); const url = `https://en.wikipedia.org/wiki/All-time_Olympic_Games_medal_table`; const res = await page.goto(url); const html = await res.buffer(); const dom = new JSDOM(html); const tables = dom.window.document.querySelectorAll('table'); for (let i = 0, len = tables.length; i < len; ++i) { const ws = XLSX.utils.table_to_sheet(tables[i]); fs.writeFileSync( `./tmp/${String(i).padStart(2, '0')}.csv`, XLSX.utils.sheet_to_csv(ws) ); } await browser.close(); })();
このページには16個のTabeleがありました。
一番ファイルサイズの大きい「01.csv」が、国別のオリンピックメダル数のTableでした。
解説
page.goto()のレスポンスが、ページのhtmlになります。- jsdomを使って、htmlからDOMを作成しています。
Document.querySelectorAll()で全てのTableタグのDOMを取得しています。- xlsxを使って、TableタグのDOMから、Excelのワークシートを作成しています。
- xlsxを使って、ExcelのワークシートからCSVを出力しています。
応用
ページ全体を取り込むのではなく、取り出したいTableタグのみを抽出することも可能です。
クロール先のサイト内でXMLSerializer.serializeToString()を使ってTableタグ以下をhtmlにして、
それをNode.js側に持ってきて、Node.js側でDOMを再構築します。
import * as puppeteer from 'puppeteer'; import { JSDOM } from 'jsdom'; import * as XLSX from 'xlsx'; import * as fs from 'fs'; (async () => { const browser = await puppeteer.launch({ headless: false, slowMo: 250, }); const page = await browser.newPage(); const url = `https://en.wikipedia.org/wiki/All-time_Olympic_Games_medal_table`; await page.goto(url); const html = await page.$eval('div.legend + table', (dom: any) => { return new XMLSerializer().serializeToString(dom); }); const dom = new JSDOM(html); const table = dom.window.document.querySelector('table'); const ws = XLSX.utils.table_to_sheet(table); fs.writeFileSync( `./tmp/medal_table.csv`, XLSX.utils.sheet_to_csv(ws) ); await browser.close(); })();
感想
これでDOMのパースのストレスから開放されました!
DOMはNode.js側にあるので、ライブラリを使って他にも色々できそうです。