Spark(Google Dataproc)から、Microsoft SQL Server(Azure Database)にアクセスする方法です。
手順
Spark設定
下記のSparkの設定をすると、SparkからSQL Serverのデータの読み書きができるようになります。
- MS SQL ServerのJDBCのjarファイルをダウンロードします
- SparkにJDBCのjarファイルを読み込みます
- 「spark-defaults.conf」の「spark.jars」にjarファイルのパスを設定します
- SparkのClassPathにJDBCのjarファイルを設定します
- 「spark-defaults.conf」の「spark.driver.extraClassPath」にjarファイルのパスを設定します
Dataproc設定
Dataproceはマネージドサービスのため、Sparkを直接いじることができません。
代わりに、Dataproceの「クラスタープロパティ」と「初期化アクション」を使って、 クラスター作成時にSparkの設定します。
事前に、MS SQL ServerのJDBCのjarファイルを、Google Cloud Storageにアップしておきます。
下記の初期化アクションを作って、Google Cloud Storageにアップします。
init_action.sh
#!/bin/bash JAR_PATH=/usr/local/lib/jars mkdir $JAR_PATH # JDBC SQL Server JDBC_MSSQL=mssql-jdbc-7.2.2.jre8.jar gsutil cp gs://bnobq-olive-dataproc/init-action/jdbc/$JDBC_MSSQL $JAR_PATH/
初期化アクションでは、Sparkに追加するjarファイルの置き場所を作って、StorageにアップしたJDBCのjarファイルをダウンロードしています。
クラスター作成
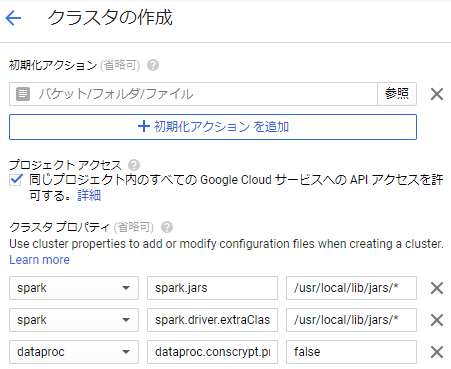
- 初期化アクション
- 先程Google Cloud Storageにアップした初期化アクションファイルを指定します
- クラスター作成時に、このアクションが実行されます
- プロジェクトアクセス
- チェックを入れる
- 初期化アクションで、StorageからJDBCのjarファイルをダウンロードしているため、クラスターにStorageへのアクセス権限を付与します
- クラスタプロパティ
- [spark]:[spark.jars]:[/usr/local/lib/jars/*]
- 「spark」でSparkの設定「spark-defaults.conf」を設定します
- 「spark.jars」「/usr/local/lib/jars/*」で、SparkにJDBCのjarファイルを読み込ませます
- [spark]:[spark.driver.extraClassPath]:[/usr/local/lib/jars/*]
- 「spark」でSparkの設定「spark-defaults.conf」を設定します
- 「spark.driver.extraClassPath」「/usr/local/lib/jars/*」で、SparkにClassPass情報として、JDBCのjarファイルを読み込ませます
- [dataproc]:[dataproc.conscrypt.provider.enable]:[false]
- 未設定の場合、ssl関連のエラーが出るため、「false」にセットします
- [spark]:[spark.jars]:[/usr/local/lib/jars/*]
利用例
options = {
"url":"jdbc:sqlserver://<server>:1433;databaseName=<db_name>",
"driver":"com.microsoft.sqlserver.jdbc.SQLServerDriver",
"dbtable":"<table_name>",
"user":"xxxx",
"password":"xxxx"
}
df = spark.read.format("jdbc").options(**options).load()
df.show()
その他感想等
読み書き両方が可能です。
タイムアウトになりやすいので、「spark-defaults.conf」の「spark.executor.heartbeatInterval」と「spark.network.timeout」を 長めに設定した方がいいかと思います。
Spark2.4以降なら、「dbtable」の代わりに「query」として、クエリでデータを取得できて便利なので、 イメージはSpark2.4が使えるバージョン1.4以上にした方がいいです。
Scalaだと専用のコネクターがあるのですが、 Pythonには無いので、JDBCで汎用的にアクセスしています。
参考記事
- https://kontext.tech/docs/DataAndBusinessIntelligence/p/connect-to-sql-server-in-spark-pyspark
- https://github.com/GoogleCloudPlatform/dataproc-initialization-actions/issues/177
- https://stackoverflow.com/questions/32958311/spark-adding-jdbc-driver-jar-to-google-dataproc
- https://stackoverflow.com/questions/52046004/how-do-i-connect-spark-to-jdbc-driver-in-zeppelin
- http://mogile.web.fc2.com/spark/sql-data-sources-jdbc.html